This is the last post for this project. I will be discussing the optimization opportunities and how I identified them. In the previous post, I discussed my benchmark results for the Aarch64 and x86_64. The timing difference between the two is due to optimizations in the code where x86_64 had optimized code while the Aarch64 did not which is why we can see the difference in timing when we made our benchmarks. In this post I will select a optimization that was made in the x86_64 that has not been made in the Aarch64. Note, optimizations were not made in the Aarch64 yet because it is still too new, which gives us an opportunity to provide an optimization for the Aarch64 architecture.
Finding Optimization
Finding what to optimize, I am currently running perf on the x86_64 and the Aarch64. One of the challenges I came to face was that my Aarch64 machine did not come with built in perf. Sicne this was the case, I set out to build my own perf for this kernel. Below is the results of my adventure, perf record and report works but with debug symbols disabled for the kernel.
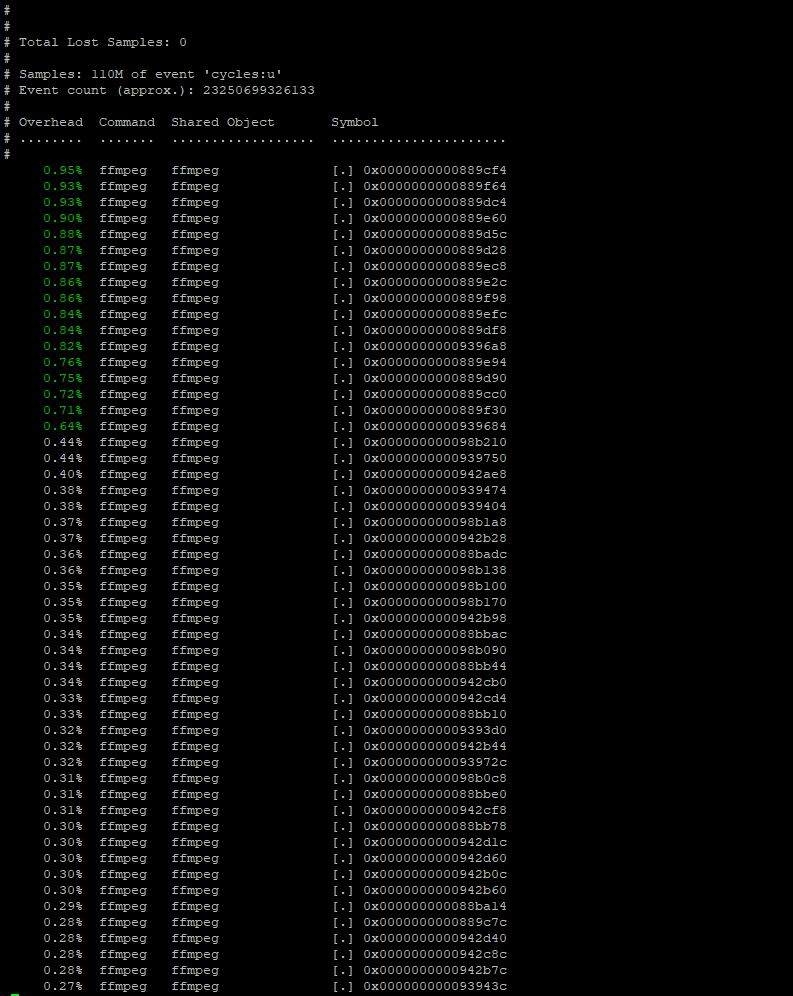
I am currently comparing files between x86_64 version of ffmpeg and the Aarch64. While some files may be optimized in Aarch64, it only had 49 files compared to the 522 file in the x86 directory. This may indicate that there were more optimization files in the x86_64 platform. Below are images of files with the extension asm. These files are used to compile assembly language code in the x86_64 platform.
In the Aarch64, there are optimization files, but they are saved using the “S” or “s” extensions.

An example of an optimization done for both the Aarch64 and the x86_64 are the videodsp files. In Aarch64 you will see optimization done in the file videodsp.S and in the x86_64, you will see the file videodsp.asm. These optimizations are done in assembly language for both platforms.
Optimization
Optimizations I found that were done in the x86_64 are:
h264_deblock.asm
lossless_videodsp.asm
These optimizations were not done in the Aarch64. The h264_deblock is responsible for improving video quality, which is done after a video has been decoded. A possible way to speed up this process is to apply similar optimizations done in the x86 platform and optimize it for the Aarch64. Another optimization that could possibly be done is a lossless compression optimization. this is not done on the Aarch64. When I ran my benchmarks Aarch64 had double the time ran when converting video from mp4 to avi format.
Conclusion
In conclusion, if we were to implement a lossless compression and deblocking optimization for the Aarch64 platform, I believe that the benchmarks would have been reduced in time. One of the SIMD instructions I would look into is the FMADD, which was found in the x86_64 file, lossless_videodsp.asm. This instruction multiplies the values in the first 2 input registry, then adds the result with the third input registry and puts the result in the destination registry. I would try to incorporate this multi scalar vector into the Aarch64 system using Neon Intrinsic equivalent of either the 64bit or 16bit functions:
float64x1_t vfma_f64 (float64x1_t a, float64x1_t b, float64x1_t c)
float64x1_t vfma_n_f64 (float64x1_t a, float64x1_t b, float64_t n)
float16_t vfmah_f16 (float16_t a, float16_t b, float16_t c)
