Profiling – FFMPEG
Profiling is used to determine which function of the software utilizes the most resources when executing itself. For me, it will most likely be the encoding aspect of the software that takes up the most resources when executing the script above. On x86_64, I wil be using the perf record command, which takes an instrumental approach to obtaining the information I need. It does this by taking snapshots of the software while it is executing and stores it into a perf.data file. This snapshot is taking thousands of times during the execution process. Using x86_64, I will determine the functions or method that takes up the most CPU time. Here is a script to get ready to analyze which function takes up the most CPU time.
mkdir ~/ffmpeg-test && \
ffmpeg -f lavfi -i testsrc=duration=388800:size=qcif:rate=9 ~/ffmpeg-test/testsrc.mp4 && \
time ffmpeg -i ~/ffmpeg-test/testsrc.mp4 ~/ffmpeg-test/testsrcTime.avi && \
perf record ffmpeg -i ~/ffmpeg-test/testsrc.mp4 ~/ffmpeg-test/testsrcPerf.avi && \
perf record – FFMPEG
In the previous post we prefixed our command with time which gave us information regarding user, system, and real time. This time around we are going to prefix our command with perf record. Perf record interrupt the program frequently, called sampling to find how much time a program spends in a specific function. Once perf record is done, we then call perf report. After this command we end up with the image below showing which function took up the most CPU time.
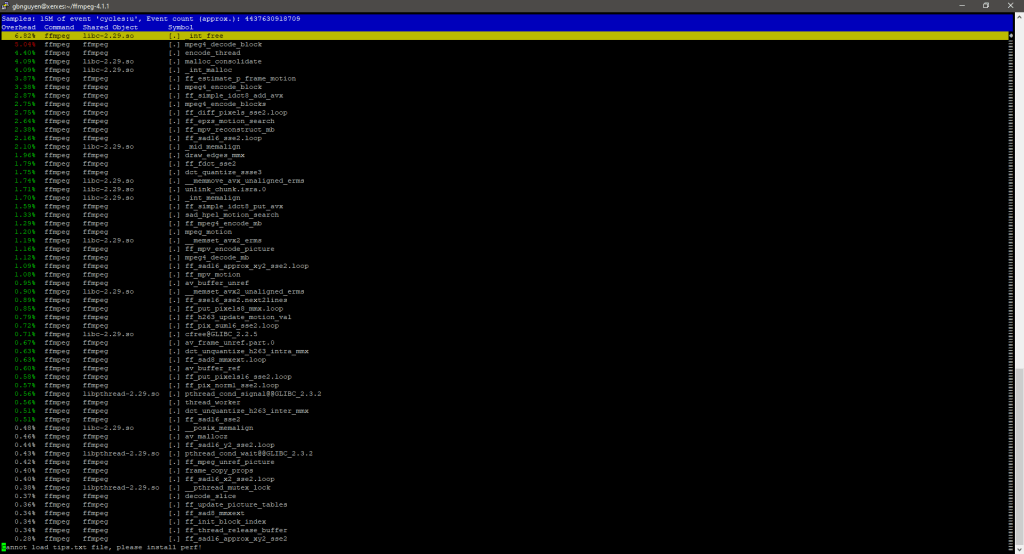
Hottest Function – FFMPEG
The function that takes up most of the CPU time when running my test was a function in a shared library libc-2.29.so. This library is called a shared library for ffmpeg and it is part of the standard C library. The function within the standard library that was taking up most of the CPU is called _int_free. Within this function the C compiler calls an instruction set.
lock cmpxchg %rbp, (%rsi)
This function compares the current value stored in the %rax register with the value stored in the register %rbp. If the values are equal, then %rsi is loaded into %rbp. If they are not equal then the value in %rdp is loaded into the %rax register. This function seems to compare the values stored in two registers. Since this software finds patterns to compress video into images, I assume that the cmpxchg instruction allows it to allocate memory for images that are unique throughout the video. This function seems to be another form of memory allocation for C.
Since the hottest function involved a shared library, I would like to pick one that is part of ffmpeg. The function I chose is mpeg4_decode_block. This function here is responsible for decoding the compressed images back into video. One of the instructions that is being sampled the most is mov, with slight more arugments.
movzbl (%r15, %rax,1), %eax
Breaking down what this instruction does is that it moves a byte with zero extension into a 32 bit register. It will take the low byte and set the high bytes all to zero and store it into a 32bit register. mov is the normal move instruction, z means zero, and l means 32bits.
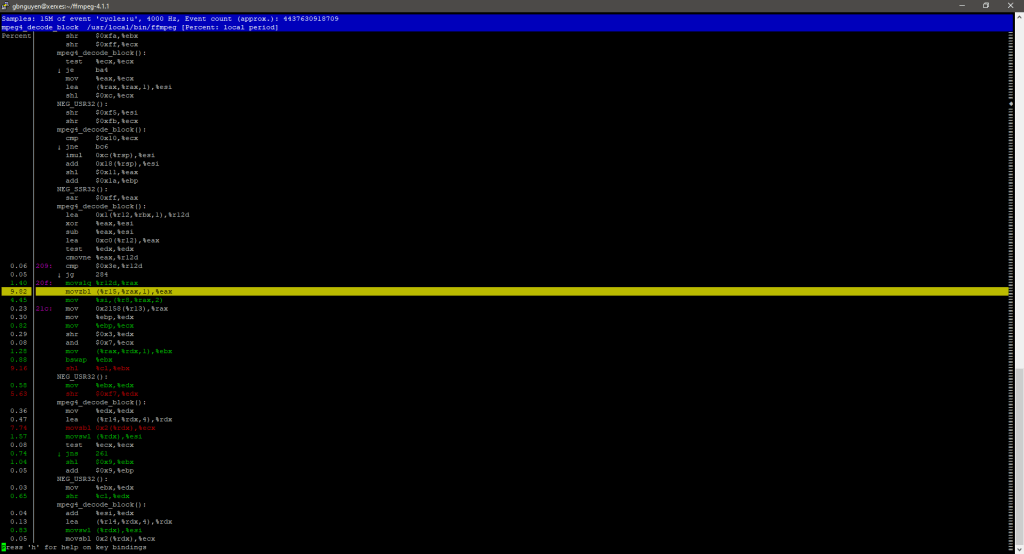
Instruction Sets – FFMPEG
Within this the mpeg4_decode_block function, most of the CPU time was taken up by mov or sh instructions. sh instructions are shifting instructions that either shift bits to the left or the right with the overflowed bits stored in the carry flag.
Conclusion
In conclusion, using perf, I was able to pinpoint which function took up the most CPU time. Although I was lucky to get the sampling right, for some cases sampling is not exact because it takes thousands of samples per second, but if a function that has one line of code is executed multiple times, but not when a sampling happens, then we may miss that function call. A way to avoid this is to increase the data size. My test video was 108 hours long. In my next post, I will be discussing how I identified optimization opportunities in the software.

One thought on “Third Project Post”